Aside from my day job and writing blogs, I teach the odd IT infrastructure courses in universities in the south of France, especially Bachelor degree students. Anyway, I usually get students that are on the junior side in terms of infrastructure knowledge. Data protection and recoverability concepts are often foreign to them and, although I teach a VMware oriented course, I try to incorporate these along other more general and important material to prepare them for real world use cases. In this blog I want to talk about Disaster Recovery (DR), Business Continuity (BC) and High Availability (HA).
I wanted to cycle back to these because my last class struggled a bit to grasp the differences at first, even though they did great and smashed their exams in the end! While my articles on this blog are usually focused on fairly focused technical stuff, this article will take things back to the basics. The goal is to explain what each of these are, what failure scenarios they address and where they fit in the SDDC lifecycle. We’ll also see how Nakivo Backup and Replication can help with these topics.

High Availability (HA)
For most organizations out there that run production workloads in a datacenter, it is critical to ensure a good SLA (Service Level Agreement), an important metric to measure availability of a service. Many contracts established between businesses (often hosting contracts be it SaaS, IaaS, PaaS, XaaS for that matter) are tied to an SLA. The longer your workloads are down, the worse your SLA will be, in which case, this can trigger a penalty for the service provider.
High Availability refers to the general term for ensuring that workloads can sustain failures in the environment. This takes the form of hardware redundancy at every level (NIC, disks, LAN/SAN switches, storage array controllers, hosts, power supplies…). The point is, if something breaks it should, at worse, involve an automatic restart of the workload. Obviously if a NIC breaks in a team or a disk breaks in a RAID group, this will trigger warnings but the workloads will keep running (might lose a couple pings at worse). However, if a host (vSphere ESXi) suddently dies for whatever reason, the virtual machines will go with it. In which case, vSphere HA paire with shared storage will save the day by automatically restarting the virtual machines on other hosts in the cluster.
In a nutshell, high availability offers resiliency to failures by restarting VMs when vSphere hosts fail.
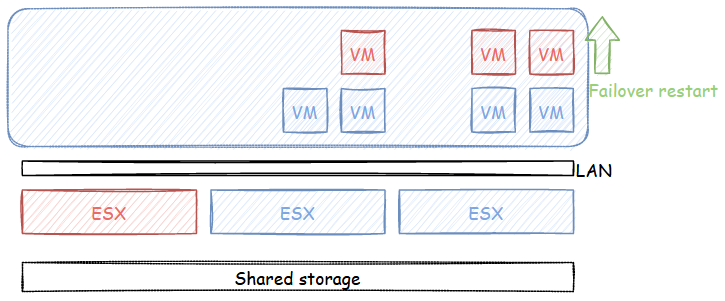
Disaster Recovery (DR)
vSphere High availability protects you against failures in a cluster within a site, but what happens should the building go down in flames or get hit by a meteorite? This is where disaster recovery plans come into play. They are drawn up to orchestrate the restore process of the impacted workloads in a recovery site. The process is often lengthy and complicated but it can be greatly simplified with tools like Nakivo Backup and Replication.
In the case of Disaster Recovery plans, there usually is one or more sites running live production workloads and one or more recovery sites that only offer capacity to take over if something fails in the production sites. It is not uncommon for companies to use recovery sites to run development or test machines so the capacity isn’t sitting there doing nothing. In case of failover, tools like Nakivo can orchestrate the shutting down of these VMs to make room for the restored production VMs. Those virtual machines can be restored because they are replicated from the production site to the recovery site at a specific interval (which equates to the RPO or recovery point objective, i.e. the amount of data you can afford to lose). Restoring replicated VMs is much faster than restoring from backups as the VMs are already registered in vCenter and stored in proper storage rather than a slower backup repositories.
When talking about disaster recovery instead of business continuity, it usually means that the sites are routed and don’t share stretched storage, the reason for VM replication. If there is no overlay solution like VMware NSX, each site will have different subnets. Meaning the IP of the VMs being recovered must be changed to match the subnet of the site. This is cumbersome and often generates a lot of work for infrastructure and dev teams to figure out what works and what breaks with IP changes. In a perfect world, everything is properly registered in a replicated DNS zone and everything uses FQDNs rather than IPs. Unfortunately, the reality of it is much different and applications must be tested independantly.
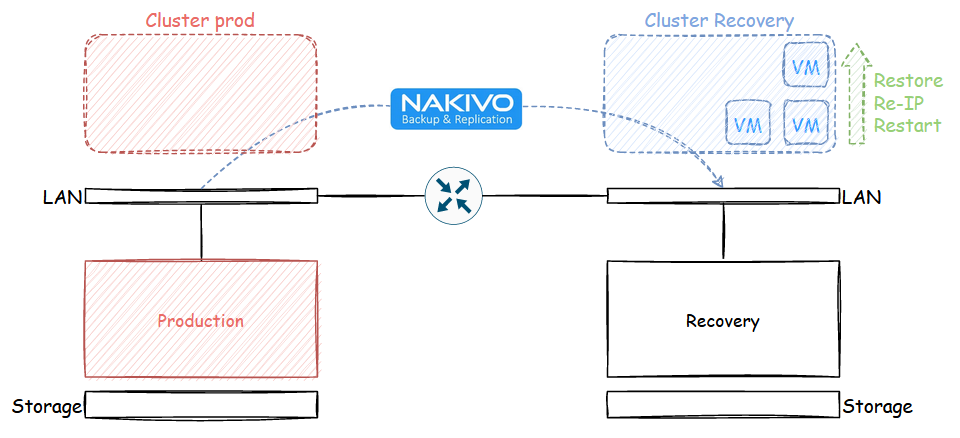
Business Continuity (BC)
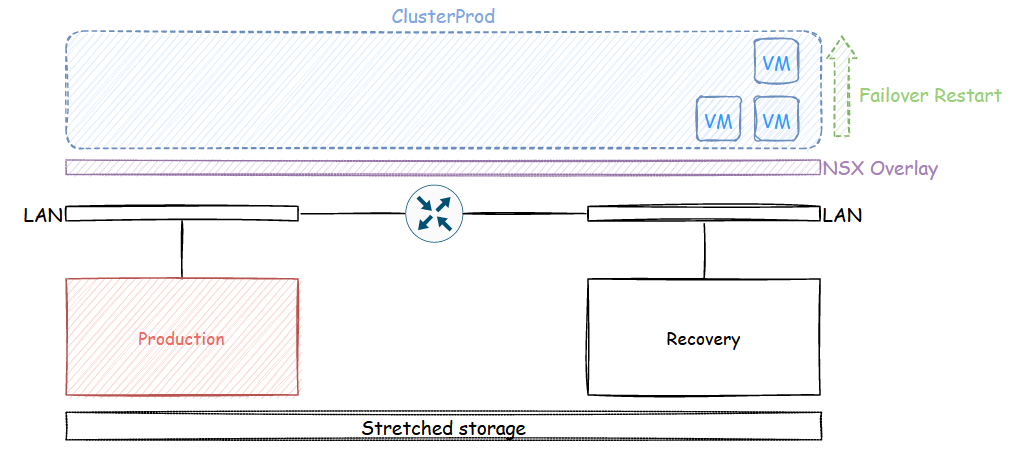
Business continuity focuses on keeping operations running during a disaster as opposed to restoring data. Specific production environment require RPOs and RTOs that are much smaller than that of a DR, in which case, a Business continuity plan is the way to go.
Rather than restoring workloads following a DRP, it will make use of high availability features such as vSphere HA so the VMs go through a simple restart following a failover action. This is very often achieved by stretching vSphere clusters across sites with stretched storage. VSAN offers stretched clusters architectures with fault domains or traditional storage array vendors often include synchronized storage like EMC’s VPLEX for instance. In order for this to happen transparently, the VMs must be on the same subnet regardless of the site they reside on, for that reason the network side of things is often overlayed with NSX in order to have the same layer 2 subnets over L3 boundaries without having to span VLANs across sites (bad practice !). These obviously lead to more expensive implementations compared to Disaster recovery plans which are asynchronous.
Some critical organizations cannot even tolerate the time it take for vSphere HA to restart the virtual machines should a host fail. Such use cases include medical facilities or stock brokers to only name a couple but I’m sure you can think of other scenarios. VMware vSphere includes Fault Tolerance, a feature where you can have a synchronous copy of a virtual machine running on a different host that will take over in case the primary VM fails. This feature isn’t used very often as it is quite cumbersome and needy in terms of requirements. In fact I have never seen a single Fault Tolerance enable virtual machine in my years as a VI admin.
Wrap up
This is a topic I very much enjoy talking about and in this article I obviously only skimmed the surface as we could write several series of books about it. The goal being to present the differences to beginners in a simple and accessible way. In the end, all three concepts we introduced here complement each other. While they can work hand in hand, choices are often bound to cost hierarchy. By that I mean that HA is the bare minimum to implement in any vSphere infrastructure, Disaster Recovery can be achieved for fairly cheap but can be complicated to create, maintain, test and execute, although you can use solutions like Nakivo Backup and Replication to reduce overhead. Lastly, business continuity greatly simplifies VM recoverability but is a lot more expensive as you need to account for stretched storage and overlay networking.