I recently had to deal with a situation were our vCenter server was unreachable. This vCenter runs vCenter HA (VCHA) and each node runs on a different ESXi host in a 3 hosts cluster thanks to an anti-affinity DRS rule.
The management IP would not reply to ping. I opened the virtual console on the active node and I noticed that only a handful of services were running. The command to start all the services would be of no use ‘service-control –start –all’ so I didn’t dig deeper in this direction. I then tried to ping the VCHA interface of the other 2 nodes and none of them replied. At first I thought about destroying VCHA but this issue didn’t make sense, vCenters don’t just break like that. So I opened a console on the passive and witness nodes and they could ping each other on the VCHA interface but not the active node.
Pretty strange, I proceeded to migrate (vMotion) the active to another ESXi host and the connectivity was suddenly restored. All the vCenter services started up again and everything came back to normal.
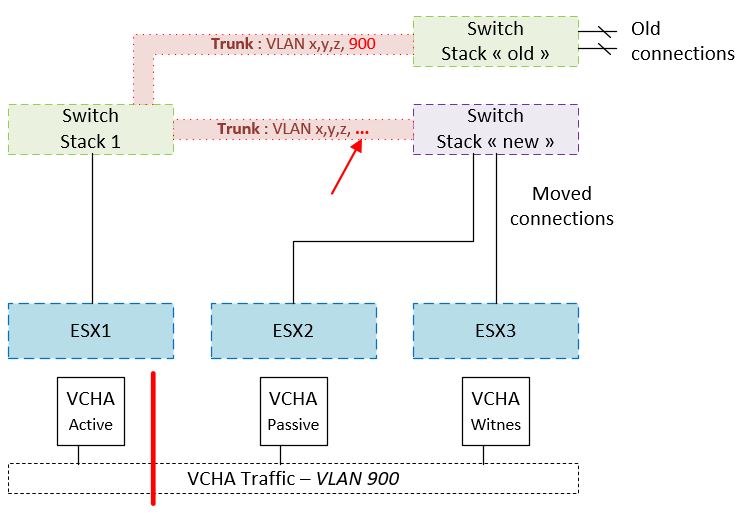
It turns out the datacenter team had moved some cables as part of a “planned” maintenance in which 2 of the 3 hosts were moved to another switch stack. However the network team forgot to add the VLAN of the VCHA traffic in the trunk that links the new stack.
VLAN not in the trunk. No VCHA traffic.
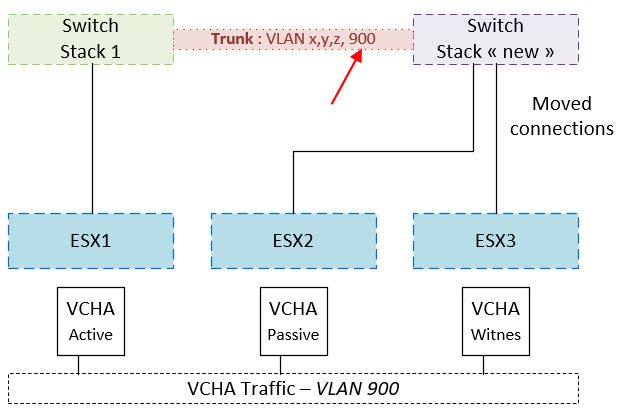
VLAN in trunk. VCHA traffic restored.
Moral of the story: If your VCHA enabled vCenter disappears, check the VCHA traffic network before dropping a nuke on it.